
1. 이미지 분할
사람의 시야는 일부분 겹쳐서 보이는 사물과 배경을 매우 쉽게 구분한다. 이러한 부분에서 불과 몇 면전까지 머신 러닝을 통한 영상 처리의 방법은 사람의 그것을 쉽게 뛰어넘을 수 없었다. 이를 해결하기 위해 이미지 분할 이라는 딥러닝 애플리케이션이 발전하였다. 객체 탐지를 목표로 하는 여러 모델들과는 여러 부분에서 다른데, 간단히 말하자면, 객체 탐지의 경우 대략적인 바운딩 박스로 물체의 위치를 정의하지만, 이미지 분할의 경우 픽셀 수준에서 객체의 위치를 예측한다는 점이 큰 차이이다.
유명한 모델로는 Mask R-CNN과 U-Net이 존재한다.
2. 이미지 분할 – Mask R-CNN
Mask R-CNN의 경우 페이스북 AI 리서치(FAIR)에서 발표한 이미지 분할 모델이다.[1] 이 모델은 다음과 같은 파이프라인을 갖는다.

1. Faster R-CNN구조를 통해 이미지에서 객체가 존재할 것으로 예측되는 ROI 추출
2. ROI분류기가 바운딩 박스에 어떤 종류의 물체가 있는지 예측하고, 위치와 크기 조정
3. 바운딩 박스를 통해 해당 이미지 부분의 CNN 특성 맵 추출
4. 각 ROI에 대한 특성 맵을 완전 합성곱 신경망(마지막에 밀집층을 두지 않고 온전히 합성곱 층들 만으로 이루어진 신경망)에 주입하여 물체에 해당하는 픽셀을 나타내는 마스크를 출력
이 과정을 보면 알 수 있겠지만, 결국 Mask R-CNN 모델의 경우 객체 탐지 모델에서 한발짝 더 나아가 여러가지 처리를 거쳐 픽셀 단위로 물체의 위치를 나타낸다. 이때, 완전 합성곱 신경망을 학습시키기 위해 물체의 위치정보를 갖는 이진 마스크 데이터가 필요하다. (이진 마스크는 주입되는 이미지와 크기가 같고, 오로지 물체가 존재하는 부분을 1 존재하지 않는 부분을 0으로 나타낸 2차원 배열을 의미한다.) 이미지가 n개의 다른 물체를 포함한다면, n개의 이진 마스크가 존재해야 학습시킬 수 있다.
3. 이미지 분할 – U-Net
이 모델은 프라이베르크 대학교에서 개발한 이미지 분할 모델이다. 이 모델의 경우 생의학 이미지를 분할할 목적으로 만들어졌다. 이 모델은 완전 합성곱 구조로 구성되어 있는데, 그 구조는 다음과 같다.
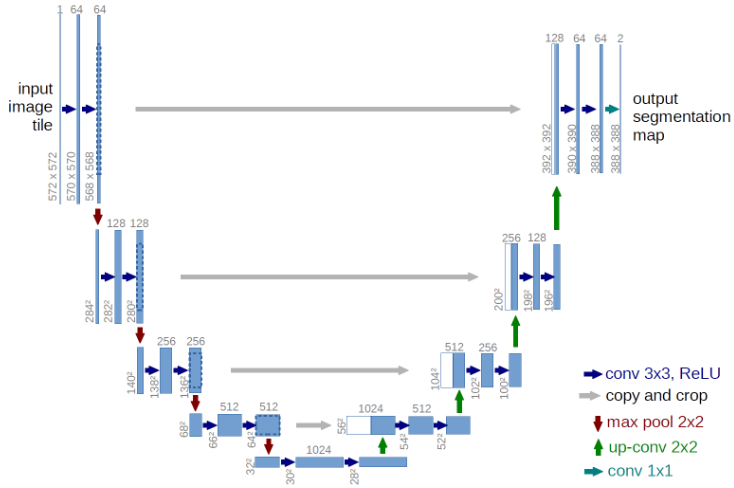
1. 압축 경로
여러 개의 합성 곱과 최대 풀링 단계를 통해 활성화 맵을 계속 작고 깊게 만든다.
2. 팽창 경로
여러 개의 업샘플링과 합성 곱 단계를 통해 깊은 활성화 맵을 원래 해상도로 복원한다.
위의 압축 팽창 경로는 서로 대칭적인데, 이러한 대칭성을 바탕으로 압축 경로의 활성화 맵을 팽창 경로의 활성화 맵에 연결하는 것이 가능하다.
모델은 압축 경로를 통해 이미지에서 고해상도 특성을 학습하고, 이 활성화 맵을 바로 팽창 경로의 활성화 맵에 연결해 고해상도 특성을 팽창 경로로 직접 전달한다. 팽창 경로의 끝에서는 모델이 최종 이미지 차원 안에 존재하는 압축 경로의 결과 특성을 손쉽게 찾아낼 수 있다. 결과적으로, 압축 경로의 특성 맵을 팽창 경로로 연결한 후 이어지는 합성곱 층으로 이런 특성을 조합하여 정확한 위치를 찾아낸다.